As we already discussed the Blog App in the last chapter, let’s look at the services and their interactions again in the following diagram:
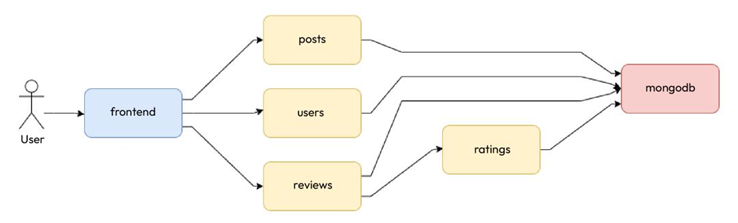
Figure 13.2 – The Blog App services and interactions
We’ve already created CI and CD pipelines for building, testing, and pushing our Blog Application microservices containers using GitHub Actions and deploying them using Argo CD in a GKE cluster.
If you remember, we created the following resources for the application to run seamlessly:
- MongoDB – We deployed an auth-enabled MongoDB database with root credentials. The credentials were injected via environment variables sourced from a Kubernetes Secret resource. To persist our database data, we created a PersistentVolume mounted to the container, which we provisioned dynamically using a PersistentVolumeClaim. As the container is stateful, we used a StatefulSet to manage it and, therefore, a headless Service to expose the database.
- Posts, reviews, ratings, and users – The posts, reviews, ratings, and users microservices interacted with MongoDB through the root credentials injected via environment variables sourced from the same Secret resource as MongoDB. We deployed them using their respective Deployment resources and exposed all of them via individual ClusterIP Services.
- Frontend – The frontend microservice does not need to interact with MongoDB, so there was no interaction with the Secret resource. We deployed this service as well using a Deployment resource. As we wanted to expose the service on the internet, we created a LoadBalancer Service for it.
We can summarize them in the following diagram:
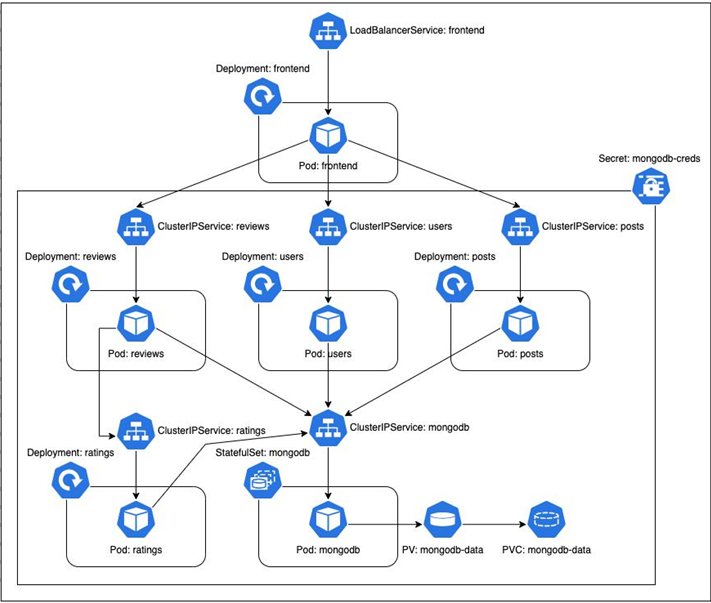
Figure 13.3 – The Blog App – Kubernetes resources and interactions
In subsequent sections, we will cover all aspects of implementing this workflow, starting with vulnerability scanning.
Container vulnerability scanning
Perfect software is costly to write and maintain, and every time someone makes changes to running software, the chances of breaking something are high. Apart from other bugs, changes also add a lot of software vulnerabilities. You cannot avoid these as software developers. Cybersecurity experts and cybercriminals are at constant war with each other, evolving with time. Every day, a new set of vulnerabilities are found and reported.
In containers, vulnerabilities can exist on multiple fronts and may be completely unrelated to what you’re responsible for. Well, developers write code, and excellent ones do it securely. Still, you never know whether a base image may contain vulnerabilities your developers might completely overlook. In modern DevOps, vulnerabilities are expected, and the idea is to mitigate them as much as possible. We should reduce vulnerabilities, but doing so manually is time-consuming, leading to toil.
Several tools are available on the market that provide container vulnerability scanning. Some of them are open source tools such as Anchore, Clair, Dagda, OpenSCAP, Sysdig’s Falco, or Software-as-a-Service (SaaS) services available with Google Container Registry (GCR), Amazon Elastic Container Registry (ECR), and Azure Defender. For this chapter, we’ll discuss Anchore Grype.
Anchore Grype (https://github.com/anchore/grype) is a container vulnerability scanner that scans your images for known vulnerabilities and reports their severity. Based on that, you can take appropriate actions to prevent vulnerabilities by including a different base image or modifying the layers to remove vulnerable components.
Anchore Grype is a simple Command-Line Interface (CLI)-based tool that you can install as a binary and run anywhere—within your local system or your CI/CD pipelines. You can also configure it to fail your pipeline if the vulnerability level increases above a particular threshold, thereby embedding security within your automation—all this happening without troubling your development or security team. Now, let’s go ahead and see Anchore Grype in action.


